

The Opsgenie incident management platform centralises and organises alerts, reliably notifies the appropriate people, and enables them to effectively communicate and take rapid action throughout an incident’s lifecycle.
Opsgenie supports native integrations for over 200 applications, including Jira Software and Jira Service Desk. For other applications, Opsgenie Integrations are made possible by utilising Opsgenie’s REST APIs or Email API.
Alert and on-call management tools are highly customisable within Opsgenie and facilitate granular control of notification preferences for services, teams and individual users. These features make Opsgenie particularly desirable as they can prevent downtime caused by overlooking major alerts, whilst stopping teams from getting distracted by being overloaded with low-priority alerts.
Core Features of Opsgenie Integration
角色
Opsgenie 定义了两种用户结构 - 响应者和利益相关者。响应者可以查看和接收通知、根据警报/事件采取行动并进行 Opsgenie 配置。利益相关者用户只能接收有关正在进行的事件的通知并跟踪其状态。
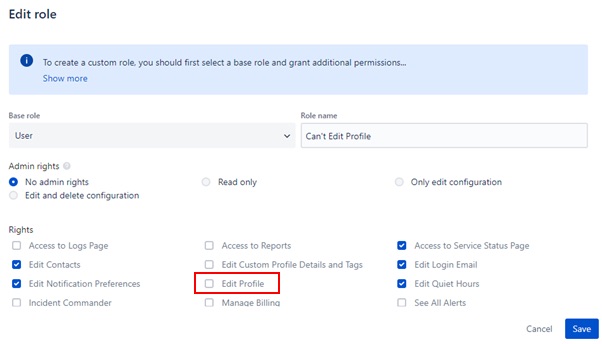
Roles can be further refined on a Global or Team level (e.g. Admin, Team Leader) to give different users different levels of configuration, and Custom Roles can be created using a default user type as a base role and configuring permissions accordingly.
用户通知定制化
每个用户都可以编辑他们自己的配置文件,从而配置他们自己的通知偏好。这包括选择他们首选的联系方式(电子邮件、短信等),并通过创建规则将不同类型的警报定向到这些联系方式。
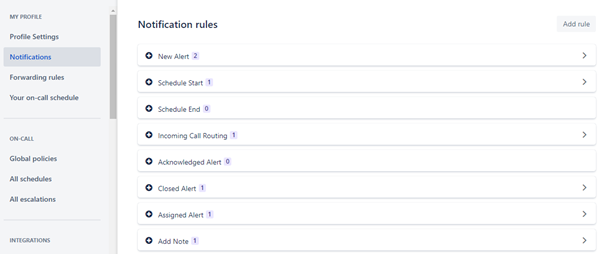
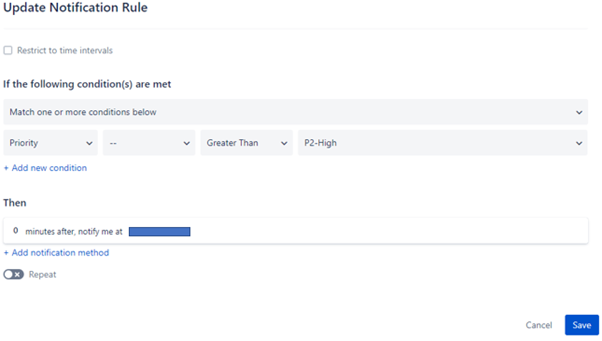
在某些情况下,用户可能不希望自己的偏好被更改。为此,应为用户分配一个禁用“编辑配置文件”权限的自定义用户角色。
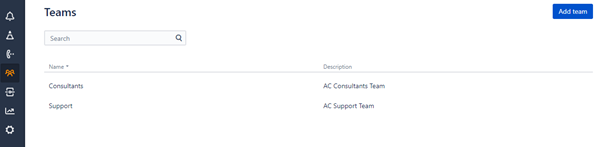
团队
团队是在 Opsgenie 中表示组织结构的一种方式。用户可以是多个团队的一部分,并在每个团队中被分配一个角色。以下部分讨论的 Opsgenie 功能是针对每个团队进行配置的。这意味着,例如,必须为每个团队单独配置与 Jira 软件开发选项的每个集成。一个团队甚至可以拥有与同一款应用程序的多个集成,这些集成也是单独配置的(例如,与 Jira 服务台选项的多个集成,每个集成都链接到不同的 Jira 项目)。
上报和值班表
Opsgenie 的一个关键功能是配置每个团队接收警报的方式。这是使用四个关键组件完成的:待命值班表、上报、路由规则和团队(或全局)策略。
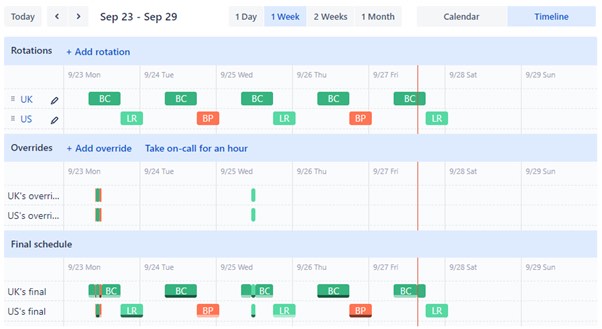
1. 待命值班表
待命值班表定义了根据日期和时间将警报路由到哪个团队成员。每个团队可以有多个值班表,每个值班表都有自定义轮换(例如主要和备用、美国和英国),这决定了哪个团队成员目前正在待命(待命用户通常是大多数警报的第一个联系人)。轮换可以包括一个或多个用户,并且可以按月、周、日或自定义(例如,仅工作日)进行配置。
覆盖的优先级高于值班表,并允许手动选择待命的团队成员。可以在任何时间执行覆盖(例如,由于疾病),最终的值班表将自动更新以考虑这些情况。
用户可以在他们的个人资料设置中选择是否接收即将开始轮换的通知以及他们希望的通知方式,他们还可以在其中查看他们所属的所有团队中的个人待命值班表。
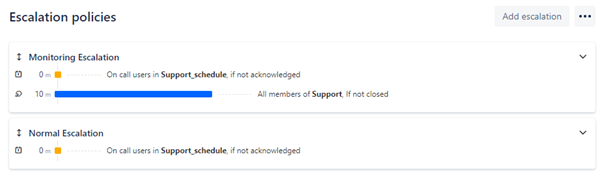
2. 上报策略
上报策略描述了当团队没有在指定的时间范围内确认或关闭警报时发生的一系列通知。例如,一个策略可能规定,一个警报最初仅通知待命的团队成员,但是如果该警报在 10 分钟后未关闭,则通知整个团队。
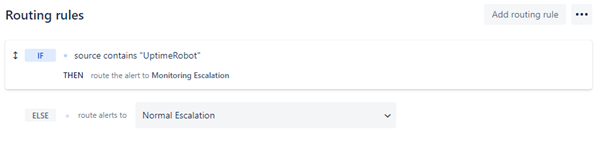
3. 路由规则
路由规则将传入警报定向到适当的上报策略。例如,规则可以基于传入警报的来源或优先级。
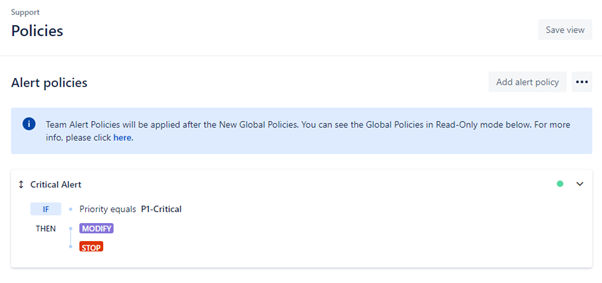
策略
可以在全局或团队级别配置警报策略(全局策略将具有更高优先级)。策略可以匹配所有传入警报,也可以仅适用于某些警报,具体取决于过滤器,例如,从特定来源创建或给定优先级的警报。如果警报满足过滤条件,则策略可以定义警报的字段(消息、优先级、描述等)并为警报分配响应者(团队、特定用户或两者的组合)。
除了警报策略,团队还可以配置通知策略,允许它们自动重启(在指定的时间之后放弃并重启通知流程)、自动关闭(在指定的时间之后关闭警报)和延迟/禁用警报。最后一项对重复的警报特别有用。
Opsgenie 中的每个警报都具有唯一的 ID(别名),并且 Opsgenie 中不能同时存在两个具有相同别名的打开的警报。因此,如果多次收到相同的警报,则不会创建新的警报 – 相反,警报计数会增加。重复的警报可能延迟,直到它们的计数达到指定数量或警报在给定时间段内出现给定次数。
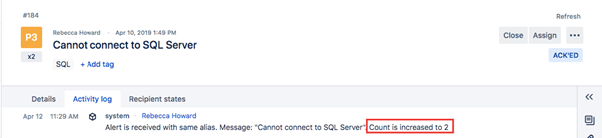
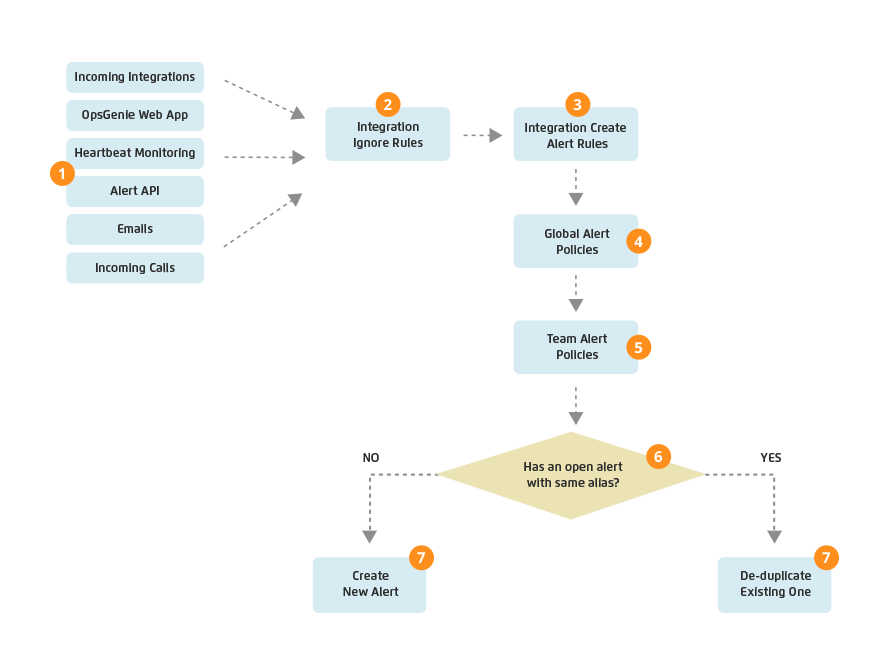
需要注意的是,除非在特定策略上启用了“继续下一个策略”,否则传入警报将仅执行它们匹配的第一个策略(顺序很重要)。如果启用了“继续下一个策略”,则处理警报策略列表中的下一个策略。此链条执行在禁用此选项的第一个策略处停止。下面的示意图说明了 Opsgenie 如何处理传入警报。
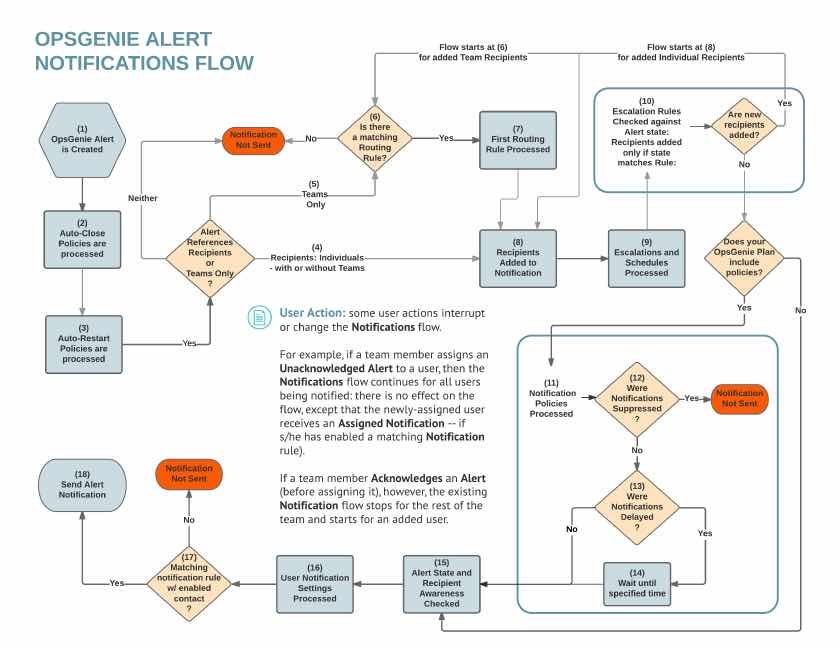
集成
Opsgenie 支持 200 多个本机集成。与之前的功能一样,集成是针对每个团队进行配置的。在每个集成的配置中,Opsgenie 提供了有关如何设置该集成的全面的分步指南。Jira 是领先的问题跟踪工具,同样属于 Atlassian,将用于演示如何与 Opsgenie 建立集成。
团队可以配置 Opsgenie 警报与 Jira 软件开发选项/Jira 服务台选项中问题的交互方式。可以从 Opsgenie 警报创建 Jira 问题,反之亦然。可以定义规则以将警报操作映射为问题操作,并过滤这些操作适用于哪些警报和问题。它们还将 Opsgenie 定向到相关的 Jira 项目。
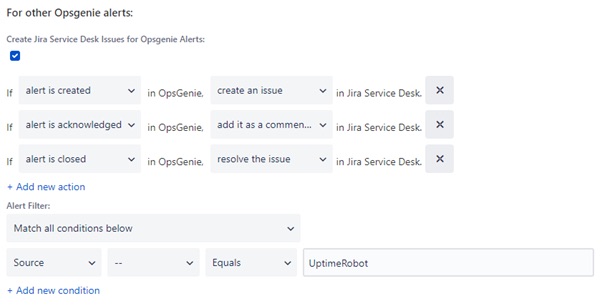
可以以类似方式设置其他本机集成。
Opsgenie 的电子邮件应用程序接口和 REST 应用程序接口可用于当前未包含在 200 个本机集成中的应用程序。例如,外部应用程序可以配置邮件处理程序,以将电子邮件定向到 Opsgenie 团队的电子邮件地址,该地址是 Opsgenie 在设置电子邮件应用程序接口集成后生成的。一个团队也可以通过配置多个电子邮件应用程序接口集成来拥有多个电子邮件地址。
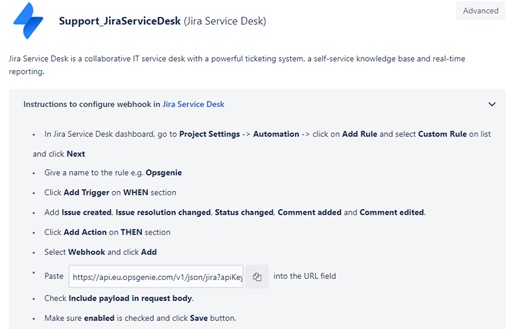
示例 - 带监控应用程序的 Jira 服务台选项
在以下示例中,团队配置了与 Jira 服务台选项的集成,以便在他们正在监控的外部服务停机时在 Jira 项目中创建问题。
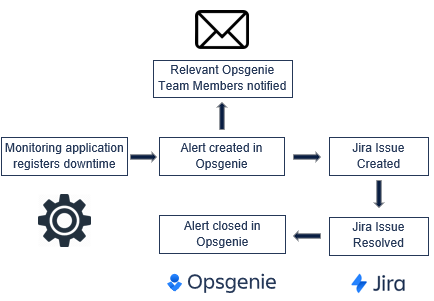
Opsgenie 在收到监控应用程序发来的通知后会创建一个警报。然后,Opsgenie 根据上述路由规则和上报策略向相关团队成员发送通知。然后通过 Jira 服务台选项集成在指定的 Jira 项目中创建一个问题。在 Jira 中解决问题后,该警报在 Opsgenie 中关闭。值得注意的是,可以将与监控应用程序的集成配置为在被监控服务再次激活时自动关闭 Opsgenie 警报(和 Jira 问题)。
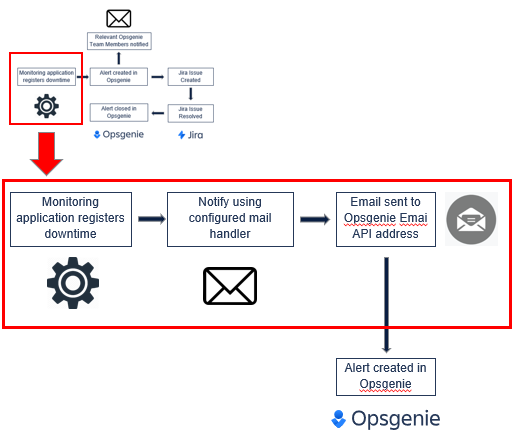
可以扩展此场景,以演示如果监控应用程序没有与 Opsgenie 的本机集成会发生什么。监控应用程序将需要额外的步骤来配置邮件处理程序,以将通知发送到电子邮件应用程序接口集成中定义的团队电子邮件地址。
服务
Opsgenie 服务为具有商业利益的服务提供单一数据源。它有助于针对给定的服务停止或中断进行事件管理。服务可以是内部的(例如登录服务),也可以是外部的(公共状态页面,例如 Jira 的状态页面)。
Opsgenie 服务是一种快速沟通和响应事件以及通知和更新相关利益相关者和订阅者的有效方式(Opsgenie 用户可以订阅服务以接收通知,只要该服务被配置为对组织公开)。每项服务(内部或外部)都需要一个所有者团队 - 该团队的成员也会自动添加为所有归因于该服务的事件的响应者。另外,还可以在服务配置中分配其他响应者(团队或个人),或者为单个事件分配其他响应者(对于利益相关者也是如此)。还可以创建利益相关者电子邮件通知模板。
可以手动(由所有者团队的管理员用户)创建事件,也可以通过警报自动创建事件,具体通过事件规则进行配置。
问题报告功能允许用户通过输入描述和严重级别来快速报告与服务相关的问题。管理员可以配置所报告问题的严重级别与所创建的相应警报的优先级之间的映射。其他用户可以通过对问题投票来增加它们的数量,然后可以创建规则,将重复出现的问题升级到更高的优先级。
例如,可以配置问题报告,以便通过某一问题创建的警报永远不会具有严重优先级(而是映射到高优先级),但是,如果任何问题报告了 3 次,则其优先级会自动设置为严重。
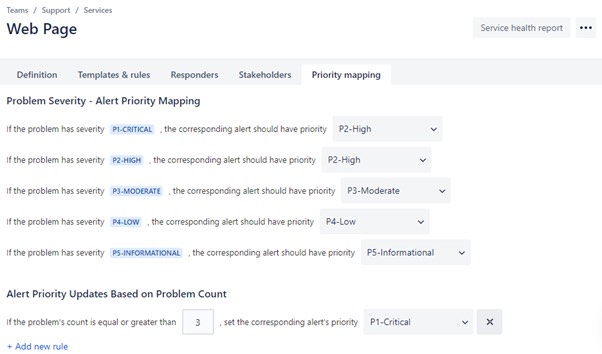
然后,可以通过定义事件规则来扩展上述示例(并显示在屏幕截图中),以根据源自具有严重优先级的服务的所有警报创建事件。结果是,如果至少 3 位用户遇到了相同的问题,就会自动为该服务生成事件。
服务通过以下方式支持响应者之间的快速轻松的沟通:
- 显示该事件中关键大事的时间表
- 会议 – 一项便于进行视频和音频通话的 Opsgenie 功能
- 分配事件响应角色:事件指挥官、通信官、抄写员、主题专家 - 这些是默认角色,也可以自定义。
解决完事件后,将创建事件后分析,以便团队能够从事件历史中吸取教训并改进未来的实践。解决事件的用户必须填写有关该事件的详细信息,包括检测、原因、缓解、解决方案。然后审查事件后分析的草稿,并且在发布之后,自动生成事件持续时间、响应时间等数据,并将其附加到事件后分析中。
心跳
心跳用于监控 Opsgenie 和其他系统之间的连接,它们可用于监控:任务、作业完成情况和系统可用性。每个系统都需要向 Opsgenie 发送一个心跳请求,同样,每个心跳都特定于一个团队。
每个系统都会定期发送基于 HTTP 的心跳,该周期可自定义为每分钟最多一个请求。如果 Opsgenie 中的心跳未能在指定的时间段内收到请求,则会创建警报。
操作
响应者在响应警报时通常会采取可预测的重复操作。其中的示例可能包括:收集有关特定系统的更多信息、运行网络诊断、增加云端资源或重启服务。Opsgenie 可用于使用可自定义的参数定义此类操作,并配置为触发这些操作以自动执行。这可以显著节省响应者的时间并减少他们需要使用的应用程序的数量。
Opsgenie 目前支持 3 种执行此类操作的方法:
- 亚马逊云计算服务系统管理器
- 通用 REST 端点
- 亚马逊云计算服务简单通知服务
分析与报告
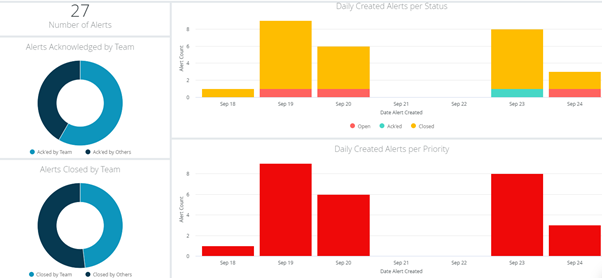
除了事件后分析外,Opsgenie 的分析功能还使用户能够访问全局、团队和用户级别的一系列报告和统计数据。这包括关于确认/响应警报的平均时间 (MTTA/MTTR)、警报类型、用户活动以及每周和每月汇总(自动生成并可通过电子邮件发送给用户)的数据。
Opsgenie Pricing Plans
The final topic that will be covered in this post is Opsgenie licensing. Opsgenie offers four plans: Free, Essentials, Standard and Enterprise. An owner of an Opsgenie instance can select which features they require and automatically be directed to the appropriate plan, however features can be added/removed after the instance has been created. All Users require a license but only Responder User licenses are chargeable – Stakeholder licenses are free of charge. For further information, see Opsgenie’s pricing information. here
感谢你抽出时间阅读本博文。如果你想了解更多信息,或者对演示文稿感兴趣,请 href=”https://www.automation-consultants.com/contact-us” target=”_blank” rel=”noreferrer noopener”>与 Automation Consultants 联系。



